I’ve opened my Visual Basic Knol to “open collaboration” – just like wikipedia. If it gets spammed to hell – I’ll close it. An experiment.
It’s now showing in the Knol index – great.
I’ve opened my Visual Basic Knol to “open collaboration” – just like wikipedia. If it gets spammed to hell – I’ll close it. An experiment.
It’s now showing in the Knol index – great.
On reading this morning that Google has opened Knol to everyone, I thought I should have a go. There seems to be a predominance of medical Knols right now, so my Knol redresses the balance by covering a programming topic. Here it is:
I deliberately did not look at whatever Wikipedia already has on the subject; knowing how good Wikipedia is on technical topics I am sure it is much longer and better than mine, and probably less opinionated.
Now I’m going to sit back and let the world improve my Knol.
But will anyone find my Knol? Oddly, if I try a search for Visual Basic on the Knol home page, my article doesn’t come up, although I’ve published it:
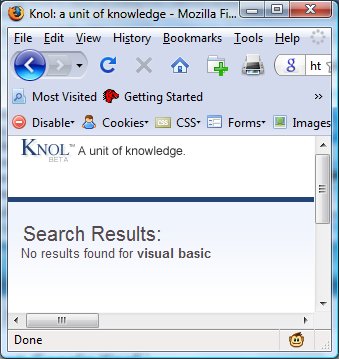
Oh well, maybe it is still being indexed.
It seems to me that the rating system is key here, and one to which I gave too little attention last time I thought about Knol. The thing is, there’s nothing to stop someone else writing an article about VB, and if it gets rated higher (sniff), my contribution will be lost at the bottom of the Knol dustbin – because I suspect Google will use the ratings heavily when ranking Knols in searches.
Other points of interest: I started creating my Knol in IE7, but gave up because of script errors and continued in FireFox. Second, I tried to verify my identity by telephone, but this only works for USA telephone numbers. It’s a beta.
Update: Danny Sullivan has a good commentary. I agree with him about credit cards. I declined.
Desktop Keeley is a new Adobe AIR application from UK tabloid newspaper The Sun. If you are foolish enough to pass this dialog:
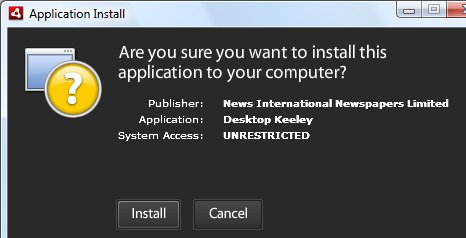
then you can benefit from:
Gorgeous Keeley is here to ease you through your day, putting a smile on your face and providing up to the minute sport info, showbiz gossip and news updates direct to your desktop.
She is too. No dull rectangular Windows; Keeley pops right onto your desktop. The default preferences reveal the target readership:
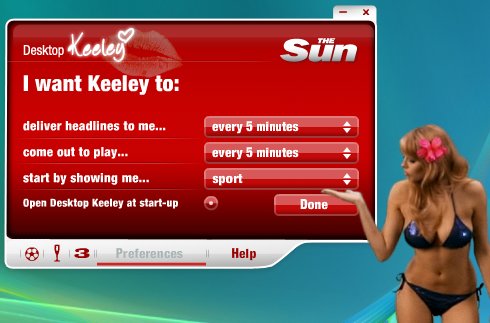
Keeley has a variety of animations and – credit where it’s due – the application is nicely done. From time to time she pops up and scribbles “Get back to work” on your screen. According to journalism.co.uk it broke Sun’s download records in three days.
Now if Microsoft had done Bob like this…
Seriously – what with Adobe Reader 9 and now this, AIR is everywhere, or will be soon.

Not that there’s anything wrong with a CD, when done right. Still, if you pay extra for something like a Linn Studio Master, at 96kHz / 24 bit resolution, you expect something which has better-than-CD audio quality (44.1kHz / 16 bit), even though some experts argue that you cannot hear the difference.
One audio enthusiast opened his Studio Master download in a sound editor and couldn’t make sense of what he saw. The conclusion, after some discussion: most likely the signal passed through digital conversion at 44.1KHz at some point in the recording process, making true 96kHz / 24 bit resolution impossible.
It would be interesting to know how many SACD or DVD Audio releases suffer from similar limitations.
Escherman’s Andrew Smith, in technology PR, asks whose site traffic figures do you trust – Google’s (via Ad Planner), or the site owner?
I don’t have Ad Planner, but because I run AdSense I can see Google’s stats on Adsense views on this site. I also have web logs, analyzed via awstats.
I took a look at my own figures for June. My stats show about 6.5 times more page views than AdSense reports.
This isn’t hits vs pages, incidentally. “Hits” record every request, so a page with several images requires several hits. Hits is therefore always the biggest number, but pages is in theory more meaningful.
It is a huge discrepancy. What’s the reason? I can think of several:
Still, 6.5 times is a huge difference, more than I would expect. The page view discrepancy on the site Smith chose to look at is a mere 4.2 times – though we don’t know how that particular web site calculates its figures.
I don’t have any firm conclusions, though my own figures suggest that any web site which simply quotes figures from its logs will come up with something much larger than Google’s filtered stats.
I’d have thought the answer for advertisers would be to use tracking images and the like in ads so they can get their own statistics.
Finally, this prompts another question. Just how much Web traffic is bot-driven? We know that somewhere between 65% up to, by some estimates, 90%+ of email is spam. Web crawlers and RSS feeds are not bad things, but they are not human visitors either. Add that to the spam bots, and what proportion does it form?
Thawte is a supplier of digital certificates. I’ve used the company to purchase certificates for code-signing.
Today I received an email inviting me to complete a customer survey. I think it is genuine: if I look at the email headers, the source domain belongs to a marketing company called Responsys which lists Verisign as a customer. Verisign owns Thawte.
I clicked the link to do the survey. Immediately I was asked to give my username and password into a web page owned by Taylor Nelson Sofres plc which is a market research company. Again, looks genuine.
What username and password? Well, I’m presuming it’s the credentials for my Thawte account that are being requested. Either that, or it’s a very broken survey.
I don’t get this. An authentication company sends me an (unsigned) email asking me to hand over my credentials to a third-party marketing company?
Could it be a phishing scam from someone who has hacked into these domains? It’s possible – I’ve emailed Thawte to complain so I may discover if this is the case.
Or just another example of woeful security on the Internet?
Update: just received an email apology from Thawte:
I wanted to reach out and apologize. The partner survey that was sent out to all recipients will be resent later on today with the correct link which will not require you to supply a user name and password.
Agreed, that you should not supply login credentials to a third party website.
Faulty survey, or a hasty change of mind? Let’s assume the former.
Lukas Biewald of Facestat says Amazon S3, which is business-critical, is his #1 cause of failure:
Using Amazon’s S3 has about the same cost and complexity as hosting the images ourselves, but we had thought that the reliability of Amazon would be significantly higher. But that now seems wrong….It’s astonishing that serving content off our own boxes can be more reliable than serving content off of Amazon.
He’s also discovered that the SLA is not worth much – the business cost of the recent 7 hour downtime is far in excess of the 25% fee rebate.
S3 is cheap. Personally I think it is unrealistic to make S3 your storage service, have no plan B, and expect high reliability.
Amazon has a case to answer too. Salesforce.com has now just about lived down its 2005 outages; but incidents like these are terrible publicity for any cloud provider.
At least, not according to Jeff Barr, Amazon’s Web Services evangelist. I was reminded of this when reading Om Malik’s post on the recent S3 outage, in which he quotes Antonio Rodrigez who asks:
… if AWS is using Amazon.com’s excess capacity, why has S3 been down for most of the day, rendering most of the profile images and other assets of Web 2.0 tapestry completely inaccessible while at the same time I can’t manage to find even a single 404 on Amazon.com? Wouldn’t they be using the same infrastructure for their store that they sell to the rest of us?
I asked Barr a question along similar lines at Qcon London in March. My concern was whether the business model (S3 is cheap) would break once Amazon had to invest in new servers purely to support S3. This is what he told me:
It’s a common misconception that we launched this simply because we had servers sitting around and we wanted to find something for them to do. It’s always been the case that we launched this specifically because we wanted to bring something of value to developers … Our community is about 330,000 developers now.
I presume that there is nevertheless considerable synergy between S3 and Amazon’s own need for distributed storage, and that there is shared software, data centres, and so on. With hindsight I should have pressed Barr further on what is shared and what is distinct. But it isn’t, apparently, excess capacity. I consider this an advantage.
Update: If Barr wants to correct this misconception he could start by clarifying the wording on the S3 home page:
…it gives any developer access to the same highly scalable, reliable, fast, inexpensive data storage infrastructure that Amazon uses to run its own global network of web sites. The service aims to maximize benefits of scale and to pass those benefits on to developers.
I wanted to adapt my Silverlight CRUD sample (which I also ported to Adobe Flex) to fix a glaring weakness, which is that any user can amend any entry.
I decided to add some logic that allows editing or deleting of only those rows created during the current session. The idea is that a user can amend the entry just made, but not touch any of the others.
WCF has its own session management but this is not supported by the BasicHttpBinding which is required by Silverlight.
Fortunately you can use ASP.NET sessions instead. This means setting your WCF web service for ASP.NET compatibility:
[AspNetCompatibilityRequirements(RequirementsMode = AspNetCompatibilityRequirementsMode.Required)]
Then you can write code using the HttpContext.Current.Session object.
This depends on cookies being enabled on the client. In my simple case it worked fine, in both Silverlight and Flex. In a real app you would probably want to use HTTPS.
I’d post the sample but unfortunately my Windows web space doesn’t support WCF.
Short comment in IT Week:
http://www.itweek.co.uk/itweek/comment/2222045/cloud-suspicion-hangs-online-4124287
The article was prompted by this incident. Of course I asked Apple to comment but it has declined to do so.