It’s three hours since I reported a phishing site to both IE7 and Firefox (Google). I revisited the site in both browsers. At first, Firefox displayed the site as before; but then I switched it to query Google dynamically. Presto! this appeared:
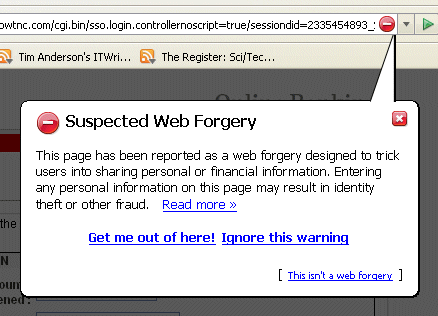
Note that the dynamic query setting is not the default, presumably because of its privacy implications. However, it is clearly more effective than the default downloaded list.
At the time of writing, IE7 is still saying “this is not a reported phishing site”; even though I reported it several hours ago.
This research is not bullet-proof. For all I know, someone else reported the site yesterday. Still, it’s an indication.
I’m still not clear why these browsers can’t figure out that this looks like a banking site, it’s asking for a password, but it’s not an SSL connection – perhaps we should alert the user. That doesn’t strike me as particularly advanced analysis.
See here for an update.
You write: “I’m still not clear why these browsers can’t figure out that this looks like a banking site, it’s asking for a password, but it’s not an SSL connection – perhaps we should alert the user. That doesn’t strike me as particularly advanced analysis.”
If you’ll show me an algorithm for determining that “this looks like a banking site”, then I’ll campaign to get it added to Firefox. Unfortunately, that’s not so easy. And you wouldn’t want it warning you every time you enter any data in any non-secure site (if you did, then there’s an option for that).
Michael,
Thanks for the comment. It’s a fair point; I certainly don’t think you could reliably detect every non-SSL phishing site, but this one seems a particularly straightforward example. The words “online banking” are plastered all over the source HTML, so are the words PIN, bank account number, credit card number, mother’s maiden name etc.
I agree I wouldn’t want a warning for any data entered into a non-secure site, but I wouldn’t object to a few false positives.
Tim
The algorithm would have to determine that it’s not just a login form for an admin system or forum or something. Certainly, if it detected our company’s admin system as a phishing site, we’d be very annoyed.
Personally, I think a few false positives would result in people turning off the feature.
Regards,
Rob…
I hope some human is actually looking at the links submitted. What’s stopping someone submitting the microsoft msdn as a phishing site?
> I hope some human is actually looking at the links submitted. What’s
> stopping someone submitting the microsoft msdn as a phishing site?
Human checking is OK if it is very prompt. Microsoft would need 24hr cover.
Actually I think the automated system can work. You can can create a whitelist to ensure that known good sites are not flagged. If the site is not whitelisted, flag the site but email a human with the link. Worst case is that a good site gets flagged temporarily, then gets whitelisted.
In FireFox, you can also a report that a flagged site is actually good; presumably Google does some analysis on the good/bad reports and tries to work out the balance of probabilities.
Ultimately you have to take a view. Is it better to risk false positives, or false negatives? I think false negatives are more dangerous, so I’d tend towards risking false positives.
I suppose there could be risk of litigation if a site was incorrectly flagged – which is bound to happen sometimes, since even humans make mistakes. But the totally cautious approach is pretty much useless.
Tim