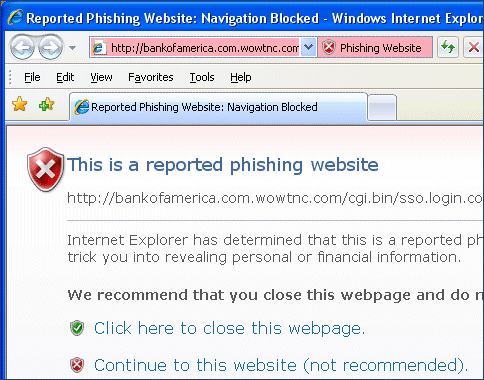
I’m now 24 hours into my attempt to use IE7 in place of my previous dedicated blog reader. It’s tolerable, but only just.
On the positive side, feeds are neatly presented and work well with IE7 tabs. If you want to read the full text or comments for a post, right-click the header and choose Open in New Tab. This is particularly handy for slow pages; you can carry on reading the feed while the all the ads and stuff on sites like news.com open in the background in the new tab.
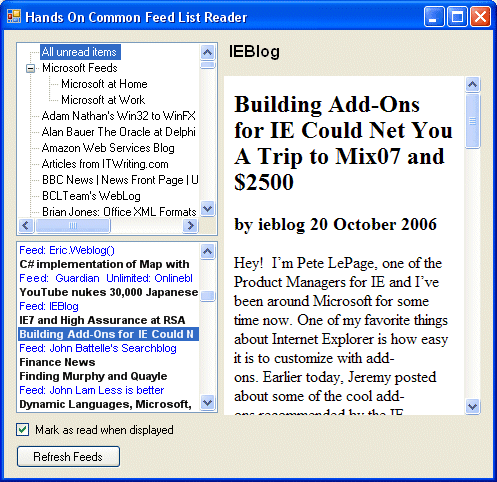
So what’s wrong with it? The biggest problem is that IE7 has no real concept of a feed item. It must be there internally, but it isn’t exposed. This messes up the management of read/unread items. You cannot mark an item as read or unread; you can only mark a feed as read. For example, say you select a busy feed like Engadget and there are 6 unread items with those large shiny images scrolling well out of sight down the page. The top item catches your eye, so you click it to read. IE7 now considers all the other items as read as well – unless you remember to unselect “Mark feed as read” every time. As a result, you are very likely to miss some items if you use IE7 for feed reading.
Next snag: there’s no way to search feeds. This turns out to be problem with the underlying RSS platform. Unless I’ve missed it, there are no methods for searching feeds; you have to iterate through each item and search in your own code. I presume that means that the centralized RSS store has no full text index, which is a shame. Anyway, IE7 has no such feature, so if you think to yourself, “I saw that in a blog this morning…”, but can’t remember which, then you have to turn to Google or Technorati.
Third, you cannot get a single view of all unread items. This is silly, as it is almost a defining feature of an offline blog reader: “Show me my unread items”. Instead, feeds with unread items are bolded, and you have to click each one to read. Lots of mouse clicks, not nice.
Fourth, it’s difficult to organize your feeds. Feeds sort themselves alphabetically, though sometimes you have to exit and restart IE7 to sort the sort. You can drag-and-drop feeds in the list, except you can’t, because although IE7 draws a horizontal bar showing where the feed will be dropped, it doesn’t drop there at all. It goes to the bottom of the list, and re-sorts alphabetically when you next restart. You can create subfolders, but you can’t select a group of feeds and move them between folders; you have to do them one at a time.
Maybe Microsoft doesn’t really want you to read RSS feeds in IE7. Perhaps the idea is that you buy Outlook 2007, which also uses the RSS platform.
The only bright spot is the API. I was so annoyed about the folder management that I ran up VB6 and wrote some code to move all the items in one folder to another. It worked sweetly. Perhaps I will write my own blog reader; I am sure the community will soon come up with some handy RSS platform readers and managers – maybe there are some already?
Technorati tags:
ie7,
blog,
microsoft,
rss