What’s the biggest problems with Vista? Not the buggy drivers, which are gradually getting sorted. Not the evil DRM, which I haven’t encountered directly, though it may be a factor in increasing the complexity and therefore the bugginess of video and audio drivers. Not User Account Control security, which I think is pretty good. Not the user interface, which I reckon improves on Windows XP though there are annoyances.
No, my biggest complaint is performance. This morning I noticed that if I clicked the Start button and then Documents, it took around 15 seconds for the explorer window to display, fully populated. Doing this with Task Manager monitoring performance, I could see CPU usage spike from below 10% to between 55% and 60% while Explorer did its stuff.
Explorer gets blamed for many things that are not really its fault. Applications which integrate with the desktop, such as file archive utilities, hook into Explorer and can cause problems. I tried to figure out what was slowing it down. I opened up Services (in Administrative Tools) and looked at what was running. It didn’t take long to find the main culprit – Windows Search:
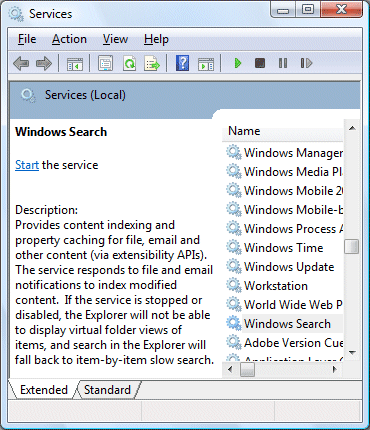
You will notice that the above dialog shows that the service is not running. That’s because I stopped it. The difference is amazing. The Documents folder now shows in less than a second. When I click the Start button, the menu displays immediately instead of pausing for thought. Everything seems faster.
Looking at the description above, it is not surprising that there is a performance impact. The indexer gets notified every time you change a file or receive an email (if you are using Outlook or Windows Mail). The same service creates virtual folder views in Explorer, a poor man’s WinFS that should make the real location of files less important. Notice that the explanatory text warns me that by stopping the service I lose these features and have to “fall back to item-by-item slow search”.
I think it should say, “If the service is started, Explorer will take fifteen times longer to open and your system will run more slowly.”
Desktop search is a great feature, but only if it is unobtrusive. In Vista, that’s not the case.
This kind of thing will vary substantially from one system to another. Another user may say that Windows Search causes no problems. I also believe that the system impact is much greater if the indexer has many outstanding tasks – such as indexing a large Outlook mailbox, for example. Further, disabling Windows search really does slow down the search function in Explorer.
Turning off Windows search is therefore not something to do lightly. It breaks an important part of Vista.
Still, sometimes you need to get your work done. That fifteen seconds delay soon adds up when repeated many times.
In truth, we should not be faced with this decision. Microsoft should know better – it has plenty of database expertise, after all. There’s no excuse for a system service that slows things down to this extent.
By the way, if you have understood all the caveats and still want to run without Windows Search, until Microsoft fix it, then you must set the service to disabled. Otherwise applications like Outlook will helpfully restart it for you.
Update
See comments below – a couple of others have reported (as I expected) that search works fine for them. So what is the issue here? In my case I think it is related to Outlook 2007, known to have performance problems especially with large mailboxes like mine. But what’s the general conclusion? If you are suffering from performance problems with Vista, I recommend experimenting with Search – stop and disable it temporarily, to see what effect it has. If there’s no improvement, you can always enable it again.
It strikes me that there is some unfortunate interaction between Explorer, Search, and Outlook; it’s possible that there are other bad combinations as well.