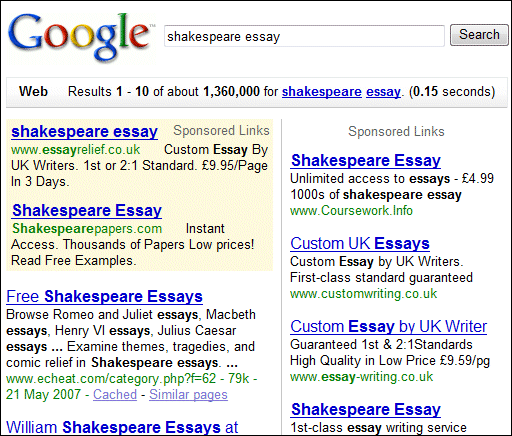
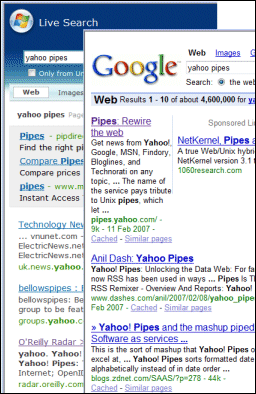
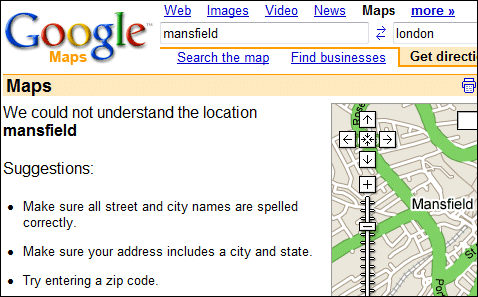
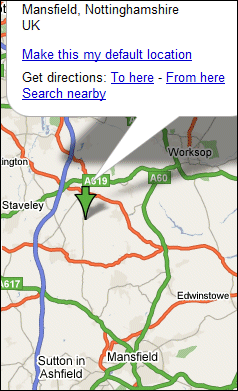
Please try the test here and vote because this is fascinating. It’s simple: perform a search and pick which is the best result, as in, which result best corresponds with what you are looking for. The script gives you the top result from Google, Yahoo and Microsoft (not in that order), but – crucially – does not show which is which. Currently, after 1400 votes, 34% have voted for the first, 53% for the second, and 29% for the third.
Of course this is an inexact science. Two different people could perform the same search and prefer different results. Further, it is not quite fair, in that the search engines could have personalization algorithms that will not operate when you go via a third-party script. I also hope nobody is cheating here, since unfortunately the test is insecure, in that you can work out which search engine is which and vote accordingly.
It is still interesting because it removes branding from the search results. This counts against Google, which has the best brand for search. After all, the brand has become a verb, “to Google”. Some people probably think Google invented web search.
Although number two is significantly ahead, the figures are already closer than actual market share would suggest. That implies that factors other than pure results are of critical performance in the search wars – though I suppose you could argue that if one search engine gives you the best result 53% of the time, you will end up using it 100% of the time.
Has anyone done a more secure test, maybe showing the first page of results rather than just the top hit?