I have a .Net project which is largely developed on a Mac using Visual Studio Code and deployed to an Azure Web App service using Azure DevOps Pipelines.
This works pretty well, though occasionally a pipeline fails because of a timeout, and works next time round.
Recently though I made some changes including upgrading to .Net 10 and migrating to Central Package Management (CPM). CPM is to my mind a great feature though seemingly little used. It means that package versions are defined in a single file at the root of the solution, and applied to all projects. Package versions are no longer specified in the individual .csproj project files. It means you have consistent package versions and simplifies upgrades. If for some compatibility reason you need different versions, there are ways to override CPM.
Everything worked fine in development but the pipeline no longer worked. The pipeline runs on Ubuntu and failed with the error:
NU1015: The following PackageReference item(s) do not have a version specified
for all the Nuget packages in the solution.
I loaded the solution in Visual Studio 2026 and everything worked fine there. I resorted to using the Visual Studio publish tool instead of the pipeline as a workaround. The pipeline works better for me though, as it runs automatically on all commits, running a suite of tests before actually deploying, and lets me work entirely on a Mac.
I made a bug report and got some well-intended advice that did not fix the problem.
Then, scrutinising the project one more time, I noticed that the documented name for the critical file that enables CPM is:
Directory.Packages.props
whereas I had:
Directory.Packages.Props
This worked fine on Windows and Mac which are mostly not case-sensitive file systems, but not on Ubuntu. I am not sure why I typed it wrong though I’ve noticed looking around that there are other references to using Directory.Packages.Props so I am not the only one.
After that I just had to figure out how to change the case of the filename on GitHub (temporarily set the config to core.ignorecase false) and everything worked.
PS: I am not sure why Visual Studio 2026 does not provide any UI for setting Central Package Management. This is likely a major reason why it is little used.
Several years ago I created a web application using ASP.NET and Azure AD authentication. The requirement was that only members of certain security groups could access the application, and the level of access varied according to the group membership. Pretty standard one would think.
The application has been running well but stopped working – because it used ADAL (Azure Active Directory Authentication Library) and the Microsoft Graph API with the old graph.windows.net URL both of which are deprecated.
No problem, I thought, I’ll quickly run up a new application using the latest libraries and port the code across. Easier than trying to re-plumb the existing app because this identity stuff is so fiddly.
Latest Visual Studio 2022 17.13.6. Create new application and choose ASP.NET Core Web App (Razor Pages) which is perhaps the primary .NET app framework.
Next the wizard tells me I need to install the dotnet msidentity tool – a dedicated tool for configuring ASP.NET projects to use the Microsoft identity platform. OK.
I have to sign in to my Azure tenancy (expected) and register the app. Here I can see existing registrations or create a new one. I create a new one:
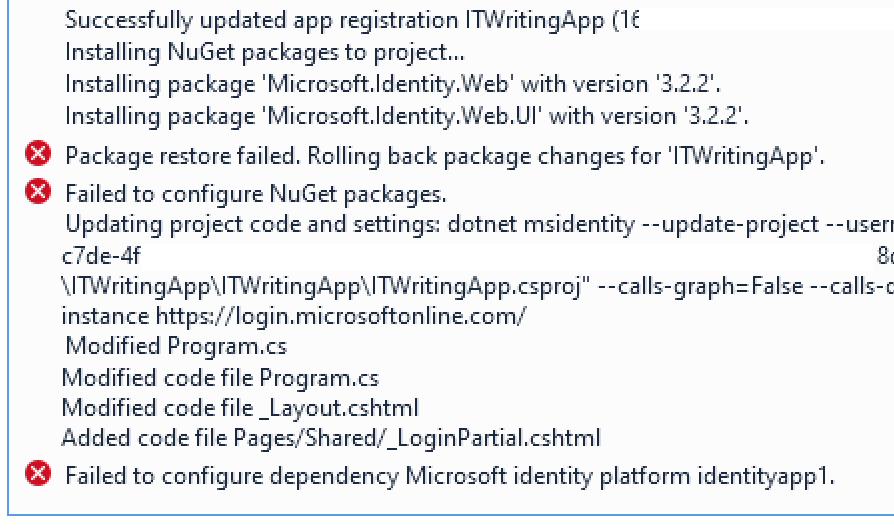
I continue in the wizard but it errors:
This does not appear to be an easy fix. I click Back and ask the wizard just to update the project code. I will add packages and do other configuration manually. Though as it turned out the failed step had actually added packages and the app does already work. However Visual Studio is warning me that the version of Microsoft.Identity.Web installed has a critical security vulnerability. I edit Nuget packages and update to version 3.8.3.
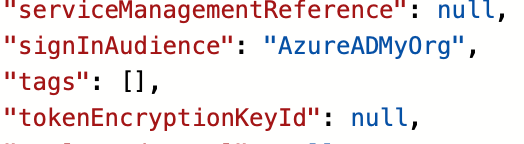
The app works and I can sign in but it is necessary to take a close look at the app registration. By default my app allows anyone with any Entra ID or personal Microsoft account to sign in. I feel this is unlikely to be what many devs intend and that the default should be more restricted. What you have to do (if this is not what you want) is to head to the Azure portal, Entra ID, App registrations, find your app, and edit the manifest. I edited the signInAudience from AzureADandPersonalMicrosoftAccount to be AzureADMyOrg:
noting that Microsoft has not been able to eliminate AzureAD from its code despite the probably misguided rename to Entra ID.
However my application has no concept of restriction by security group. I’ve added a group called AccessITWritingApp and made myself a member, but getting the app to read this turns out to be awkward. There are a couple of things to be done.
First, while we are in the App Registration, find the bit that says Token Configuration and click Edit Groups Claim. This will instruct Azure to send group membership with the access token so our app can read it. Here we have a difficult decision.
If we choose all security groups, this will send all groups with the token including users who are in a group within a group – but only up to a limit of somewhere between 6 and 200. If we choose Groups assigned to the application we can limit this to just AccessITWritingApp but this will only work for direct members. By the way, you will have to assign the group to the app in Enterprise applications in the Azure portal but the app might not appear there. You can do this though via the Overview in the App registration and clicking the link for Manage application in local directory. Why two sections for app registrations? Why is the app both in and not in Enterprise applications? I am sure it makes sense to someone.
In the enterprise application you can click Assign users and groups and add the AccessITWritingWebApp group – though only if you have a premium “Active Directory plan level” meaning a premium Entra ID directory plan level. There is some confusion about this.
Another option is App Roles. You can assign App Roles to a user of the application with a standard (P1) Entra ID subscription. Information on using App Roles rather than groups, or alongside them, is here. Though note:
“Currently, if you add a service principal to a group, and then assign an app role to that group, Microsoft Entra ID doesn’t add the roles claim to tokens it issues.”
Note that assigning a group or a user here will not by default either allow or prevent access for other users. It does link the user or group with the application and makes it visible to them. If you want to restrict access for a user you can do it by checking the Assignment required option in the enterprise application properties. That is not super clear either. Read up on the details here and note once again that nested group memberships are not supported “at this time” which is a bit rubbish.
OK, so we are going down the groups route. What I want to do is to use ASP.NET Core role-based authorization. I create a new Razor page called SecurePage and at the top of the code-behind class I stick this attribute:
[Authorize(Roles = "AccessITWritingApp,[yourGroupID")]
public class SecurePageModel : PageModel
Notice I am using the GroupID alongside the group name as that seems to be what arrives in the token.
Now I run the app, I can sign in, but when I try to access SecurePage I get Access Denied.
We have to make some changes for this to work. First, add a Groups section to appsettings.json like this:
// Add services to the container.
builder.Services.AddAuthentication(OpenIdConnectDefaults.AuthenticationScheme)
.AddMicrosoftIdentityWebApp(builder.Configuration.GetSection("AzureAd"));
and change it to:
// Add services to the container.
builder.Services.AddAuthentication(OpenIdConnectDefaults.AuthenticationScheme)
.AddMicrosoftIdentityWebApp(options =>
{
// Ensure default token validation is carried out
builder.Configuration.Bind("AzureAd", options);
// The following lines code instruct the asp.net core middleware to use the data in the "roles" claim in the [Authorize] attribute, policy.RequireRole() and User.IsInRole()
// See https://docs.microsoft.com/aspnet/core/security/authorization/roles for more info.
options.TokenValidationParameters.RoleClaimType = "groups";
options.Events.OnTokenValidated = async context =>
{
if (context != null)
{
List requiredGroupsIds = builder.Configuration.GetSection("Groups")
.AsEnumerable().Select(x => x.Value).Where(x => x != null).ToList();
// Calls method to process groups overage claim (before policy checks kick-in)
//await GraphHelper.ProcessAnyGroupsOverage(context, requiredGroupsIds, cacheSettings);
}
await Task.CompletedTask;
};
}
);
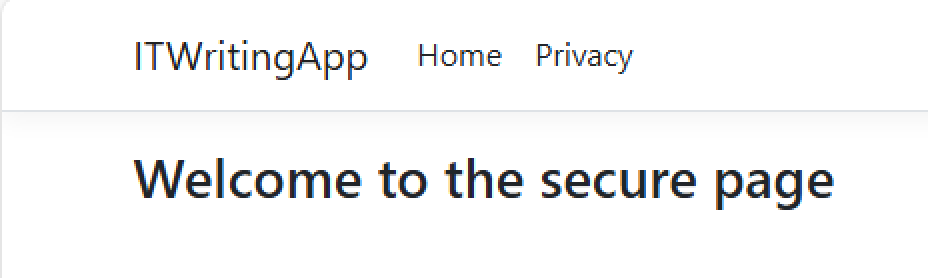
Run the app, and now I can access SecurePage:
There are a few things to add though. Note I have commented a call to GraphHelper; you might want to uncomment this but there are further steps if you do. GraphHelper is custom code in this sample https://github.com/Azure-Samples/active-directory-aspnetcore-webapp-openidconnect-v2/ and specifically the one in 5-WebApp-AuthZ/g-2-Groups. I do not think I could have got this working without this sample.
The sample does something clever though. If the token does not supply all the groups of which the user is a member, it calls a method called ProcessAnyGroupsOverage which eventually calls graphClient.Me.GetMemberGroups to get all the groups of which the user is a member. As far as I can tell this does retrieve membership via nested groups though note there is a limit of 11,000 results.
Note that in the above I have not described how to install the GraphClient as there are a few complications, mainly regarding permissions.
It is all rather gnarly and I was surprised that years after I coded the first version of this application there is still no simple method such as graphClient.isMemberOf() that discovers if a user is a member of a specific group; or a simple way of doing this that supports nested groups which are often easier to manage than direct membership.
Further it is disappointing to get errors with Visual Studio templates that one would have thought are commonly used.
And another time perhaps I will describe the issues I had deploying the application to Azure App Service – yes, more errors despite a very simple application and using the latest Visual Studio wizard.
Amazon Linux 2023 is the default for Linux VMs on AWS EC2 (Elastic Compute Cloud). Should you use it? It is a DevOps choice; the main reason why you might use it is that it feels like playing safe. AWS support will understand it, it should be performance-optimised for EC2; it should work smoothly with AWS services.
Amazon Linux 2 was released in June 2018 and was the latest production version until March 2023, by which time it was very out of date. Based on CentOS 7, it was pretty standard and you could easily use additional repositories such as EPEL (Extra Packages for Enterprise Linux). It is easy to keep up to date with sudo yum update. However there is no in-place upgrade.
Amazon Linux 2023 is different in character. It was released in March 2023 and the idea is to have a major release every 2 years, and to support each release for 5 years. It does not support EPEL or repositories other than Amazon’s own. The docs say:
At this time, there are no additional repositories that can be added to AL2023. This might change in the future.
The docs also document how to add an external repository so it is a bit confusing. You can also compile your own rpms and install that way; but if you do, keeping them up to date is down to you.
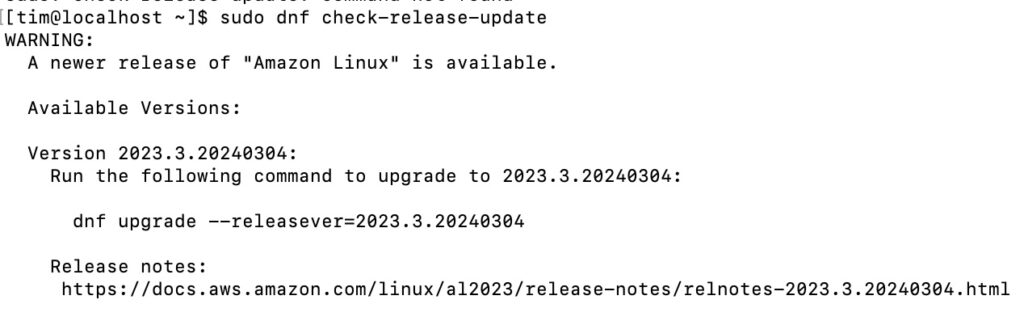
The key to why this is though is in a thing AWS calls deterministic upgrades. Each version, including minor versions, is locked to a specific repository. You can upgrade to a new release but it has to be specified. This is what I got today from my installation on Hyper-V:
Amazon Linux 2023 offering a new release
The command dnf check-release-update looks for a new release and tells you how to upgrade to it, but does not do so by default.
The reason, the docs explain, is that:
With AL2023, you can ensure consistency between package versions and updates across your environment. You can also ensure consistency for multiple instances of the same Amazon Machine Image (AMI). With the deterministic upgrades through versioned repositories feature, which is turned on by default, you can apply updates based on a schedule that meets your specific needs.
The idea is that if you have a fleet of Amazon Linux 2023 instances they all work the same. This is ideal for automation. The environment is predictable.
It is not ideal though if you have, say, one server, or a few servers doing different things, and you want to run them for a long time and keep them up to date. This will work, but the operating system is designed to be disposable. In fact, the docs say:
To apply both security and bug fixes to an AL2023 instance, update the DNF configuration. Alternatively, launch a newer AL2023 instance.
The bolding is mine; but if you have automation so that a new instance can be fired up configured as you want it, launching a new instance is just as logical as updating an existing one, and arguably safer.
Amazon Linux 2023 came out in March 2023, somewhat late as it was originally called Amazon Linux 2022. It took even longer to provide images for running it outside AWS, but these did eventually arrive – but only for VMWare and KVM, even though old Amazon Linux 2 does have a Hyper-V image.
Update: Hyper-V is now officially supported making this post obsolete but it may be of interest!
I wanted to try out AL 2023 and it makes sense to do that locally rather than spend money on EC2; but my server runs Windows Hyper-V. Migrating images between hypervisors is nothing new so I gave it a try.
I used the KVM image here (or the version that was available at the time).
I used the qemu disk image utility to convert the .qcow2 KVM disk image to .vhdx format. I installed qemu-img by installing QUEMU for Windows but not enabling the hypervisor itself.
I used the seed.iso technique to initialise the VM with an ssh key and a user with sudo rights. I found it helpful to consult the cloud-init documentation linked from that page for this.
In Hyper-V I created a new Generation 1 VM with 4GB RAM and set it to boot from converted drive, plus seed.iso in the virtual DVD drive. Started it up and it worked.
Amazon Linux 2023 running on Hyper-V
I guess I should add the warning that installing on Hyper-V is not supported by AWS; on the other hand, installing locally has official limitations anyway. Even if you install on KVM the notes state that the KVM guest agent is not packaged or supported, VM hibernation is not supports, VM migration is not supported, passthrough of any device is not supported and so on.
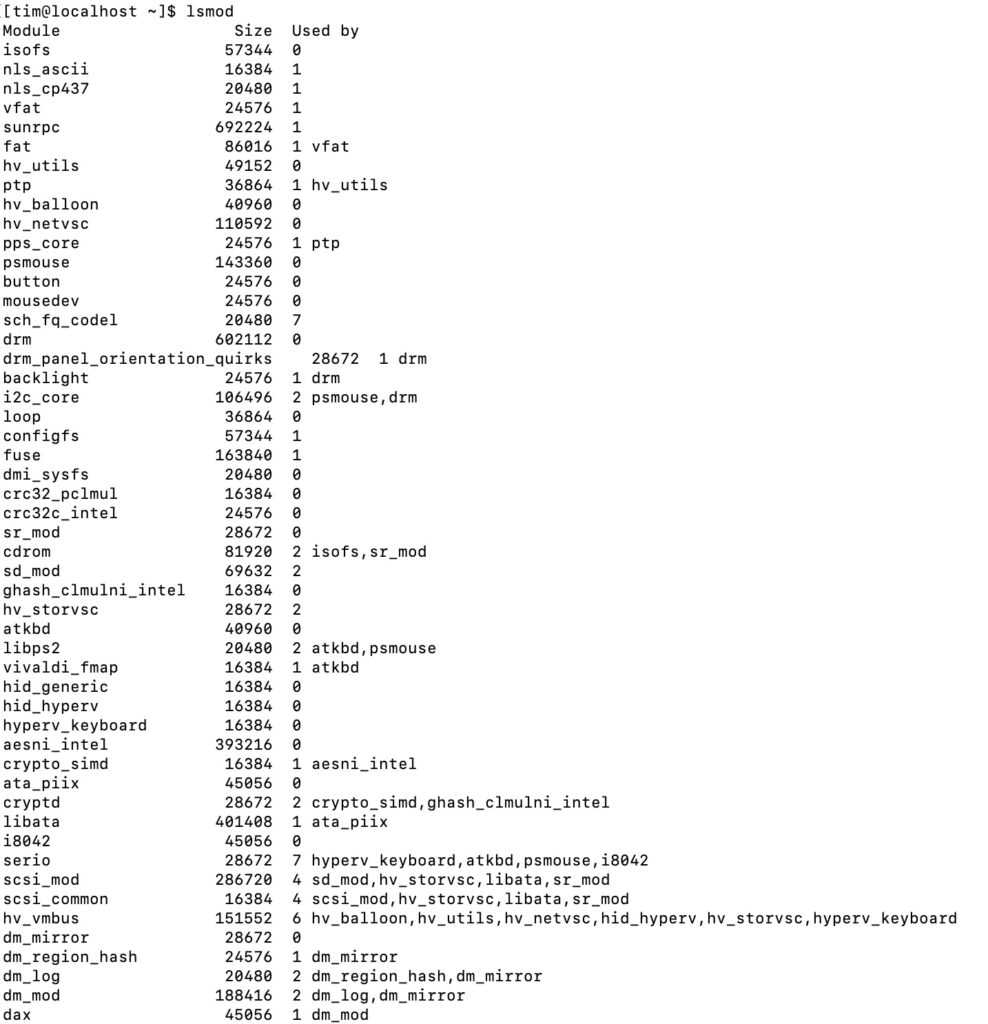
What about the Hyper-V integration drivers? Note that “Linux Integration Services has been added to the Linux kernel and is updated for new releases.” Running lsmod shows that the essentials are there:
The Hyper-V modules are in the kernel in Amazon Linux 2023
Networking worked for me without resorting to a legacy network card emulation.
This exercise also taught me about the different philosophy in Amazon Linux 2023 versus Amazon Linux 2. That will be the subject of another post.
My work PC for the last few years has been a 2018 HP Omen gaming PC which has been brilliant; I have replaced the GPU and added storage but everything still works fine. That is, it used to be, until I reviewed a mini PC which has surprised me with its capability – not because it is exceptional, but because everyday technology is at the point where having something bigger is unnecessary for everyday purposes other than gaming.
Mini PC with paperback book and CD to show the size
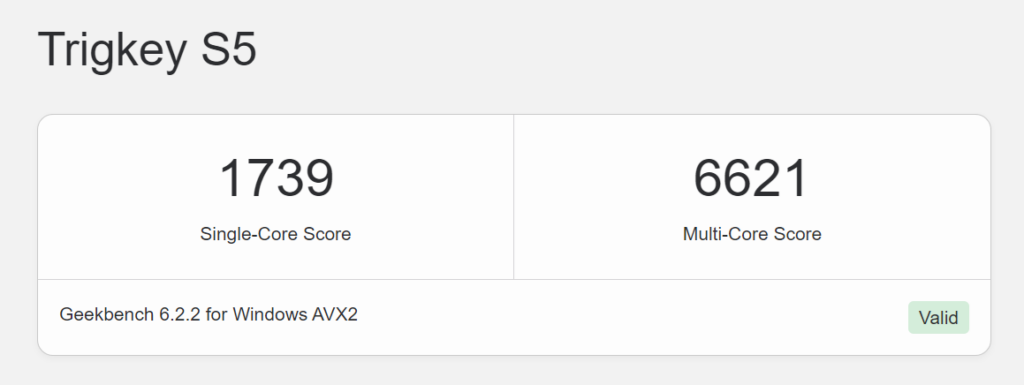
The new PC is a Trigkey S5 with an AMD Ryzen 5560 CPU, 500GB NVMe SSD and 16GB DDR4 RAM, and currently costs around £320. Its Geekbench CPU score is better than my 5-year old HP with a Core i7.
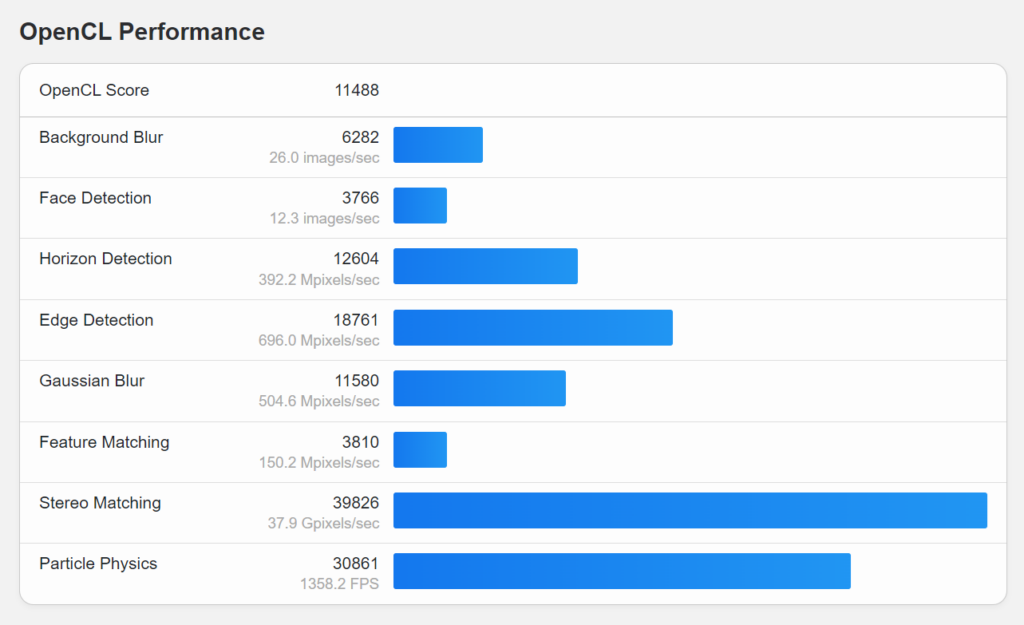
GPU score is way less than the old HP.
Still, there is support for three displays via HDMI, DisplayPort and USB-C and 4K/60Hz is no problem.
Inside we find branded RAM and it does not look as if the components are shoe-horned in, there is plenty of space.
The power supply is external and rated at 19v and 64.98w.
Expansion is via 4 USB-A ports, one USB-C, and the aforementioned HDMI and DisplayPort sockets. There is also an Ethernet port, and of course Bluetooth and Wi-Fi.
Operating system? Interesting. It is not mentioned in the blurb but Windows 11 happens to be installed, but with one of those volume MAK (Multiple Activation Key) licenses that is not suitable for this kind of distribution (but costs the vendor hardly anything). When first run Windows setup states that “you may not use this software if you have not validly acquired a license for the software from Microsoft or its licensed distributors,” which you likely have not, but Trigkey may presume that most of its customers will not care. I recommend installing your own licensed copy of Windows as I have done, or your preferred Linux distribution.
Windows does run well however and 16GB RAM is enough for Hyper-V and Windows Subsystem for Linux (WSL) 2.0 to run well. Visual Studio 2022, VS Code, Microsoft Office, all run fine.
I am not suggesting that this particular model is the one to get, but I do think that something like this, small, light, and power-sipping, is now the sane choice for most desktop PC users.
I have a lot of time for Thoughtworks, a global software development company, and always look at its Technology Radar, the latest version of which appeared recently. Plenty to digest, but what caught my eye was this comment regarding SPAs (Single Page Applications):
The sheer prevalence of teams choosing a single-page application (SPA) by default when they need a website has us concerned that people aren’t even recognizing SPAs as an architectural style to begin with, instead immediately jumping into framework selection. SPAs incur complexity that simply doesn’t exist with traditional server-based websites: search engine optimization, browser history management, web analytics, first page load time, etc. That complexity is often warranted for user experience reasons, and tooling continues to evolve to make those concerns easier to address (although the churn in the React community around state management hints at how hard it can be to get a generally applicable solution). Too often, though, we don’t see teams making that tradeoff analysis, blindly accepting the complexity of SPAs by default even when the business needs don’t justify it.
This struck a chord with me because of my adventures creating an online bridge playing platform using ASP.NET Core. I picked the platform because I was in a hurry, like C#, and had some existing code for implementing a bridge game, done for Windows. Any online game though needs lots of JavaScript and I soon became aware that the traditional ASP.NET approach, where each web page is a separate .cshtml file with server-side rendering and C# code-behind, is at odds with trends towards SPAs and JAMstack (JavaScript, API and Markup, where “Markup” is HTML and CSS).
Note that you can of course do SPAs and JAMstack with ASP.NET; ASP.NET is a nice technology for implementing an API and there are Visual Studio templates for things including “ASP.NET Core with React.js and Redux”. A Razor Pages application is still the default though, and gives you a UI for the ASP.NET Core Identity for free which saved me a lot of gruntwork. Still, as I got deeper into JavaScript libraries, including the AWS JavaScript SDK which I am using for audio and video, I found myself being steered towards React.js (resisted so far) and JavaScript bundling with Webpack (tried but was not a good fit). I also found that even switching my JavaScript code to TypeScript was surprisingly awkward, considering that the creator of TypeScript works for Microsoft. I found myself wondering if I should have started with an SPA, or convert my application to an SPA, in order to fit in well with the new world.
Separately, I’ve been involved with another project, in PHP and JavaScript, which is an SPA, and hitting some of the potential issues. For example, the application made a ton of database queries on first load, the data from which was in most cases never used, as users did not visit the parts of the application that required them. Refactoring to load this data on demand has made the application faster and more efficient.
A problem, which Thoughtworks alludes to in a remark about “closing the gap on user experience,” is that staying in JavaScript rather than loading a new page from the server generally makes for a smoother application. The way my bridge application has evolved is that the main play screen is a kind of SPA: everything is done in JavaScript and API calls, and I have written a ton of JavaScript code for things like rendering HTML tables where server-side rendering with Razor would be much easier, but unacceptable for usability. However, different parts of the application still use separate Razor pages, for things like viewing results, configuring a user profile, finding a game, and admin screens for managing members and running sessions.
JavaScript, now TypeScript, has exceeded my expectations in terms of performance and capability. It is annoying at times but a modern web browser is a phenomenal platform. I was glad though to see Thoughtworks noting that going the SPA route is not always the right decision
Someone was trying to use the bridge application I have in progress, using an iPad 2.0. There were a couple of interesting things about this. One was that I had to rethink the warning thrown up, base on Modernizr, which detects incompatible web browsers. The problem (obvious when you think about it) is that if you use some potentially incompatible features in the same page where you are testing for them, then with an old web browser the JavaScript fails with a syntax error and the warning does not appear. The fix: I now show the warning by default, and the compatibility check hides it.
Still, I was interested in the Safari error and wanted to debug it, in case it was something I could fix. How do you debug Safari on an iPad? The way it is meant to work is this:
– On a Mac, enable the Safari Develop menu (in Safari preferences, Advanced, Show Develop menu).
– On iOS, enable Safari Web Inspector (Settings – Safari – Advanced – Web Inspector).
– Connect the iPad to the Mac via USB. You can now use Web Inspector on the Mac to debug the Safari iOS pages and scripts.
This did not work for me on my Catalina Mac. The iOS Safari did not show up in the Web Inspector on Safari Mac. I could get it to show briefly, by switching Web Inspector on the iPad off and on again, but after than, no go. I tried a few things, but none of the proposed solutions I could find for this issue fixed it for me.
I have an older 2011 Mac Mini in a drawer, so I thought that might work, being a similar age to the iPad. I fired it up, marvelled at how old-fashioned the UI looked (I had reset it to OS X Lion), and connected the iPad. No go. Same problem as with Catalina.
Surprisingly, what did work were the instructions here (more or less) for debugging Safari iOS on Windows. This is based on the RemoteDebug iOS WebKit Adapter described here, a project which originated as an internal Microsoft experiment.
I did find it amusing that I could do this on Windows, having failed with the Mac.
The next generation of this is Inspect. This is in private beta, though the GitHub page for RemoteDebug says it has been superseded and to use Inspect instead.
Pipelines is an Azure service that enables a powerful feature: the ability to set up continuous integration. I have tangled with it before, in the context of trying Azure Kubernetes Service, but managed to avoid getting deep into the YAML which is the language of Pipelines. I am working on a web application and trying to get it up to scratch as quickly as possible, especially as there are now a bunch of users who are being patient over glitches during development but whose patience may run out.
The application uses .NET Core which for the most part is working well for me. I am using Visual Studio 2019, with occasional forays into Visual Studio Code (VS Code), and deploying to a Linux Azure App Service. Everything was fine until one day when the Web Deploy feature in Visual Studio stopped working with “could not complete the request to remote agent … the operation has timed out.” I appealed for help but with no result yet.
All was not lost as I found that the VS Code Deploy to Azure extension worked pretty well. All I needed to do was to open the solution folder in VS Code, run:
dotnet publish -c Release -o ./publish
in the terminal, then right-click the publish folder and then right-click the publish folder and choose Deploy to web app. There are a few annoyances but it solved the immediate problem.
One can do better though. Rather than manually deploying, you can create a pipeline using Azure DevOps (the thing that was once called Visual Studio Online and is the cloud version of Team Foundation Services). An attraction of using Azure Devops is that you get “1 Microsoft-hosted job with 1,800 minutes per month for CI/CD” free which seems decent.
I got started, creating an Azure DevOps project and adding a pipeline. You authorize it to access your GitHub repository (if that is what you have, as I do) and then end up in an editor that looks like this:
I soon got frustrated. The Pipelines service seems fundamentally excellent but spoilt by poor documentation and some odd behaviour – at least for .NET Core. It took me hours to achieve a basic setup that would upload, test and deploy my simple web application. Most of the time was spent observing pipelines fail to run and trying to figure out why.
When you run a pipeline you may notice that it uses .NET Core 2.1 and warns that 2.2 and 3.0 are end of life:
How do you get it to use .NET Core 3.1? You can add a snippet called UseDotNet@2 and specify the version. I put 3.1 and it was rejected as it likes a full version. I put 3.1.301 and it worked .
The most time-consuming thing for me was running tests. The application uses an Azure SQL database. It is unwise to put the database password in appsettings.json in the GitHub respository. How then do you connect to the database? The docs anticipate this and you can use a feature called variable substitution. In the Pipeline editor, you can add variables and mark them secret, so they are not included in logs. You can also use variables from Azure Key Vault. Then you can use the FileTransform@2 task to replace the connection string in appsettings.json with the one you need including the password. I do not think this is ideal from a security perspective – you are still putting the password in plain text in a configuration file – but it beats having it in the GitHub repository.
I had many issues. The main documentation on variable substitution is here. This is terrible. Note that if you look at the YAML example for JSON file substitution (which is what we need) it does not even use FileTransform@2. It uses AzureRmWebAppDeployment@4 which does a whole lot of other stuff as described here. Maybe I should have tried that. But FileTransform@2 looked like the right thing. Unfortunately it generally gives the error “Cannot perform XML transformations on a non-Windows platform.” No, I am not trying to do an XML transformation. Even if you specify the fileType as json and set enableXmlTransform to false, you still get the error. Later research suggests you can beat this error by setting xmlTransformationRules to an empty string. I gave up though and used FileTransform@1 (an older version of the task) which works as expected.
I still did not get the result I wanted though. All the tests using the database failed. Eventually I figured out that I had to set the folderPath to $(Build.SourcesDirectory). Then it works.
This was good. Now my tests run in Linux rather than on Windows, matching the deployed environment. In a full production environment I would use a second Azure SQL database for the tests, but for development this will do.
I then created a staging slot in the App Service and added a deployment step to deploy the application to that slot. Again, this is good. The application will not deploy unless it passes all the tests (this is a built-in feature of Pipelines, as each step does not run unless the previous steps succeeded). It deploys to staging which has a separate URL so you can try it out and not swap it to production until you are ready.
Overall, it is a better solution than the Visual Studio web deploy which it replaces, so perhaps the error did me a favour. It will work with Visual Studio as well as with VS Code, since it triggers automatically on every code commit. The Publish option in Visual Studio becomes redundant.
Note that Visual Studio also has an option to set this up automatically.
I tried it, letting the wizard do what it wanted including creating a new Azure DevOps project and a new App Service plan. Notable things:
– It created a pipeline using the Classic UI rather than the YAML based editor
– It uses an agent (the VM where the pipeline runs) called vs2017-win2016
– the pipeline did not get very far, failing on NuGet restore
No, I am not going to bother troubleshooting this.
This time yesterday I hated Azure DevOps pipelines. Nothing worked first time, YAML is a hostile editing environment (whitespace matters), and the documentation frustrated me. Now I feel pleased and I have this nice badge in my repository.
I am left with a nagging feeling though that all this is more difficult than it should be. It seems to me that what I wanted to do was commonplace: use .NET Core, use Azure App Service, have my pipeline build the project, run tests and deploy to staging. You could add, apply entity framework migrations in many cases. I did not find this documented in any one place and the result was that it took more time to figure out.
Rust is a programming language aimed at system programming – for which high performance and low-level system access is essential – but with safety features that make it harder to write dangerous or insecure code (though it is still possible). Since all programmers value both speed and stability, Rust is being used for tasks other than system programming as well. Rust is open source and sponsored by Mozilla, which uses Rust in its own development including parts of the Firefox web browser.
Rust is not one of the most-used programming languages; according to a StackOverflow survey only 3.2% of developers use it. Among professional developers that figure drops to 3.0%.
Second, Rust has built-in support for unit tests, in conjunction with Cargo, the Rust build system and package manager. Cargo will both generate test functions and run tests for you. You can do unit tests in any language, but this is a great way to prompt developers to use them. Tests are a big deal. I recall Sqlite developer Dr D Richard Hipp telling me that testing was core to the project and without it, it could not progress as it does. Sqlite has 662 times more test code than the code in the Sqlite library itself.
Fourth, Microsoft is considering using Rust on the basis that it “could eliminate an entire class of vulnerabilities before they ever happened”.
Fifth, work is under way to build a new operating system with Rust, called Redox. I wrote about this briefly for the Register.
If asked to think of a language that is as efficient and powerful as C++ but nicer and for many of us more productive to use, I think of Delphi (or Object Pascal). Delphi has an ardent niche following but is unlikely to grow its usage much beyond it. Rust on the other hand is a modern language that benefits from things we have learned about programming in the last forty years (C++ was first thought by Bjarne Stroustrup when writing his PhD thesis, though the name dates from 1983), and with a refreshing lack of legacy. And Delphi is not open source, unless you mean Lazarus.
Worth a look if you have a moment – see here for how Verity Stop got on.
I have a Mac running Catalina. It is almost new and I did not migrate anything from the old Mac, so should be a very clean install.
I installed Xcode 11 from the App Store. All fine.
Yesterday it wanted to update to Xcode 11.1. But the update took a long time and then failed. Try again later. I did. Same. The App Store UI gives you no clue what is not working.
I ran the Console app to check the log. Install failed “The package is attempting to install content to the system volume.”
Annoying. Suggested fix is to download the DMG. Another idea is to uninstall and then reinstall from the App Store. I like having it App Store managed so I did the latter and it worked.
Together with Gimp permission problems it looks like permission issues in Catalina are a considerable annoyance. Which is OK if security is better as a result; but that does not excuse this kind of arbitrary behaviour.